
The Memory Illusion: Teaching Your AI to Remember
What 'memory' really means for LLMs (hint: it's simpler than you think)


💡 Free Preview: This is normally paid content, shared openly to show the depth AlteredCraft provides. No hype, just hard-won insights.
Yesterday, I spent an hour with Claude helping me refactor our authentication service. We discussed architectural patterns, debated tradeoffs, and finally nailed a solution that cut our code complexity in half. This morning, I opened a new chat to continue our work.
"Hey Claude, about that auth refactor we discussed yesterday..."
Blank stare. Well, not literally, but you know what I mean. My AI collaborator had no idea what I was talking about. Every insight we'd developed, every decision we'd made, every bit of context we'd built was gone. If you've worked with AI tools for more than a week, you know this frustration—the perpetual starting over, the constant re-explaining, the context that evaporates between sessions.
This is the default reality for most AI interactions: each new conversation starts from zero. The reason is simple: LLMs are fundamentally stateless. They only know what's in the current prompt.
You've probably seen "memory frameworks" and "RAG architectures" pitched as solutions—LangChain, LlamaIndex, entire startups built on this promise. And yes, production systems often require that complexity. Vector databases for semantic search, sophisticated retrieval mechanisms, multi-tier architectures. But here's what gets lost in all that sophistication: at its core, memory in AI is just saving and retrieving text. It's about bringing previous conversation text back into the current prompt. That's it.
In this post we'll start with the fundamentals, a simple file-based approach that demonstrates exactly how memory works. This isn't necessarily your production solution, but it's where understanding begins. And you might be surprised how far these basics can take you.
Demystifying LLM "Memory"
Let's get precise with our terms, because understanding what "memory" actually means in AI systems will change how you build with them.
Memory in the context of LLMs means one thing: persisting portions of prompts and outputs between sessions. That's it. When ChatGPT "remembers" that you prefer TypeScript, it saved that text somewhere and can retrieve it later.
Remembering is equally straightforward: retrieving that persisted text and including it in new prompts. There's no neural pathway being strengthened, no weights being updated. Just text being added to the conversation.
This matters because LLMs are fundamentally stateless. Each time you send a prompt, the model processes it from scratch with no inherent knowledge of previous interactions.
You might ask: "How do chat interfaces maintain conversations?" They create an illusion of memory by appending your entire conversation history to each new prompt. When you type "What about the second approach?", here's what actually gets sent to the model:
What the user types:
User: "What about the second approach?"
What actually gets sent to the model:
<< all previous statements in this session with the LLM >>
...
User: How should I structure this React component?
Assistant: Here are three approaches: 1) Single file with all logic,
2) Separate hooks and components, 3) Feature-based folders...
User: What about the second approach?
The model sees everything on each request and responds as if it "remembers", since in that moment, it has access to the full context.
This architecture has profound implications for developers building with AI:
Context effectiveness degrades with size. While context windows are expanding (some models now support 1M+ tokens), research shows that LLMs struggle1 to effectively use information buried in large contexts. This "context rot" directly impacts memory systems—400 memories might consume 8K tokens but perform worse than 100 well-curated memories using 2K tokens.
Costs compound with each exchange a 10-message conversation that looks like 200 tokens actually costs 1,100+ tokens. Since each request includes all previous messages, you're paying for the same tokens repeatedly. That's not the linear growth you might expect.
Collaboration patterns need rethinking. Traditional pair programming assumes persistent shared context—something we've refined over decades into effective workflows. With stateless AI, you're constantly syncing state, which breaks the natural rhythm of building on shared understanding. This isn't just a technical limitation; it disrupts collaboration patterns that actually work well in human-to-human development.
But here's the opportunity: once you understand that "memory" is just text persistence and retrieval, you can engineer around these limitations. At its core, AI memory is a data management problem with clear parameters: what text to store, how to organize it, when to retrieve it, and how to keep it relevant.
These are tractable engineering questions. Do you need simple keyword matching or semantic search? Should persistence be file-based or database-backed? Is a full framework worth the complexity for your use case? Understanding the underlying mechanics lets you evaluate these trade-offs based on your actual needs rather than vendor promises.
When someone pitches their "cognitive architecture," you'll recognize they're solving the same text persistence challenge, just with different approaches to scale, search, and abstraction. Whether you build something custom or adopt a memory abstraction framework, you'll know exactly what you're getting and why.
How Today's Tools Handle Memory
The platforms you're already using validate our simple approach. OpenAI's ChatGPT Memory2 stores conversation facts as text snippets. No magic, just "user prefers Python" saved and retrieved. Cursor takes an even simpler approach: project rules stored as plain text files. Its hierarchical memory system uses .cursor/rules/ directories throughout your project - global rules at the root, with subdirectories containing their own scoped rules. Each rule file gets automatically included in the AI's context when relevant. Need backend-specific context? Put rules in backend/.cursor/rules/. Frontend patterns? frontend/.cursor/rules/. The AI sees the appropriate rules based on where you're working.
The revealing pattern across all these tools: they use text storage with relevance filtering, not complex cognitive architectures. Cursor powers professional development workflows with a few kilobytes of text files. OpenAI serves millions with what amounts to a smart notepad. Yes, this shifts how we think about persistent state in development tools, but these aren't temporary solutions or MVPs, they're proven architectures that work at scale. Understanding this gives you permission to start simple and add complexity only as required.
Building Memory: A Practical Journey
Let's build a memory system for Claude. Not in theory, but actual code you can run today. Our companion app3 demonstrates two levels of implementation, both simpler than you might expect.
Level 1: Simple File Persistence (40 lines of code, 20 minutes to implement)
Here's the core memory functionality in under 20 lines of Python:
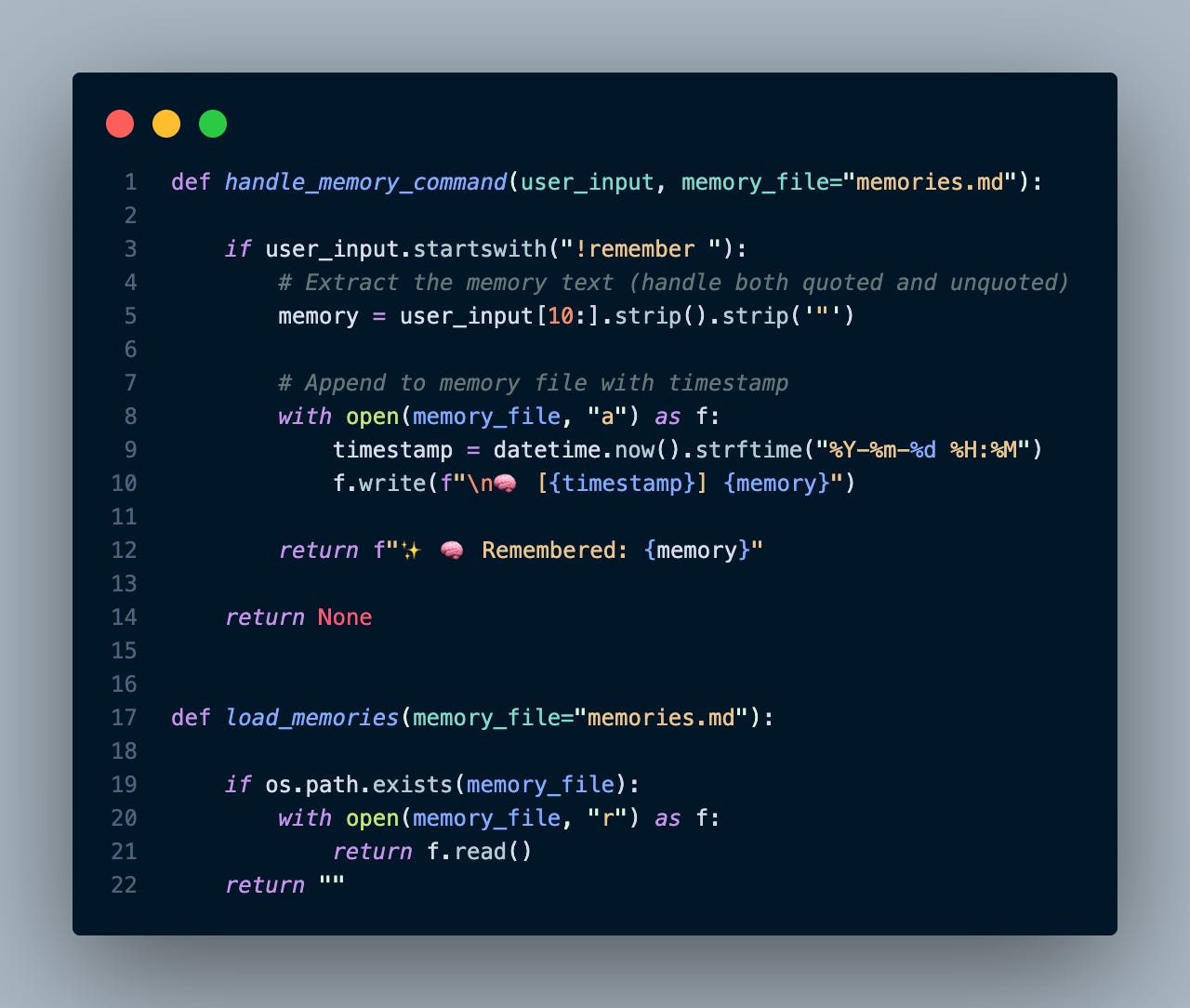
That's the core of the "memory system." When you chat with Claude:
You: Tell me about Python decorators
Claude: [explains decorators...]
You: !remember "User prefers practical examples over theory"
✨ 🧠 Remembered: User prefers practical examples over theory
You: Can you explain async/await?
Claude: [gives practical, example-heavy explanation]
The magic happens in how we use these memories. Each new conversation includes them in the system prompt:
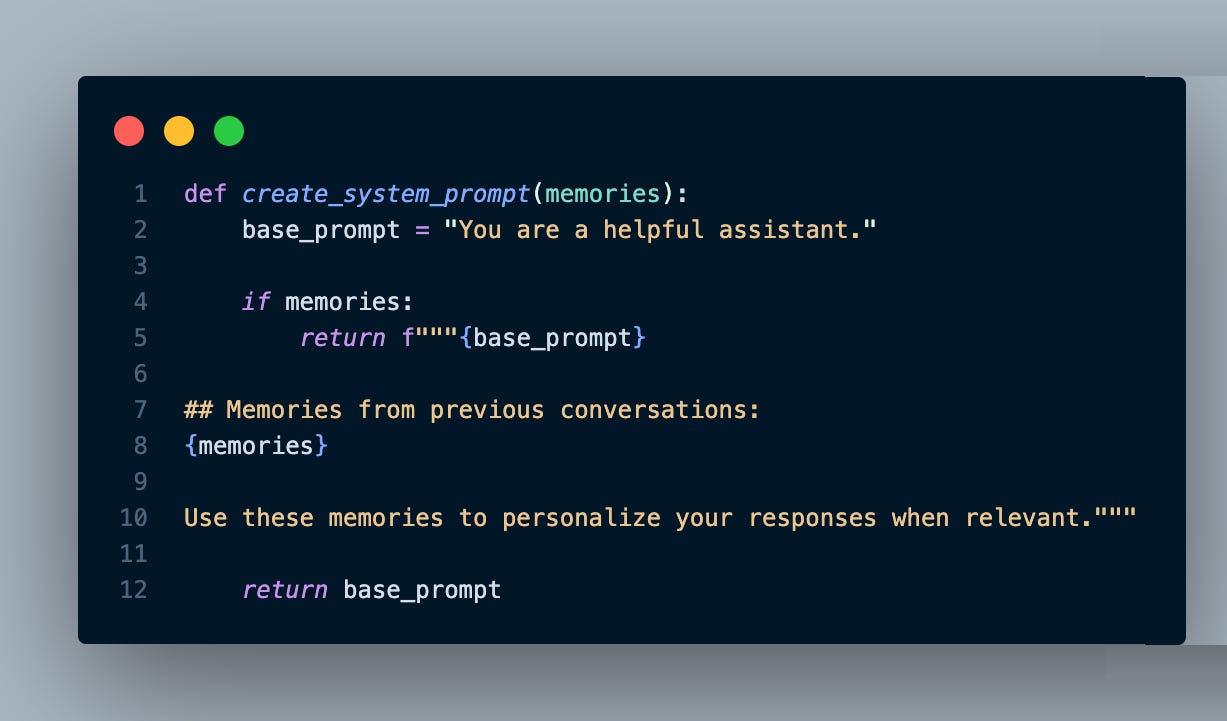
Your memory file (memories.md) looks like this:
🧠 [2024-11-15 09:32] User prefers practical examples over theory
🧠 [2024-11-15 10:45] Working on a FastAPI project with PostgreSQL
🧠 [2024-11-15 14:22] Likes concise explanations, dislikes verbose responses
🧠 [2024-11-16 08:15] Team uses Black for Python formatting with 88 char line length
This works remarkably well at this scale. Claude sees these memories every conversation and naturally incorporates them. No vector databases, no embeddings, no complexity. Just text in a file.
The companion app includes a --debug flag so you can see exactly what's being sent to Claude - demystifying the entire process. Try it and watch how simple "memory" really is.
Level 2: Smart File Processing (30 minutes to add)
As memories accumulate, you'll hit token limits. Monitor your token usage—each memory costs roughly 20-30 tokens, so 100 memories means 2-3K tokens on every request. Our Level 2 implementation adds a compaction routine triggered by !compact:
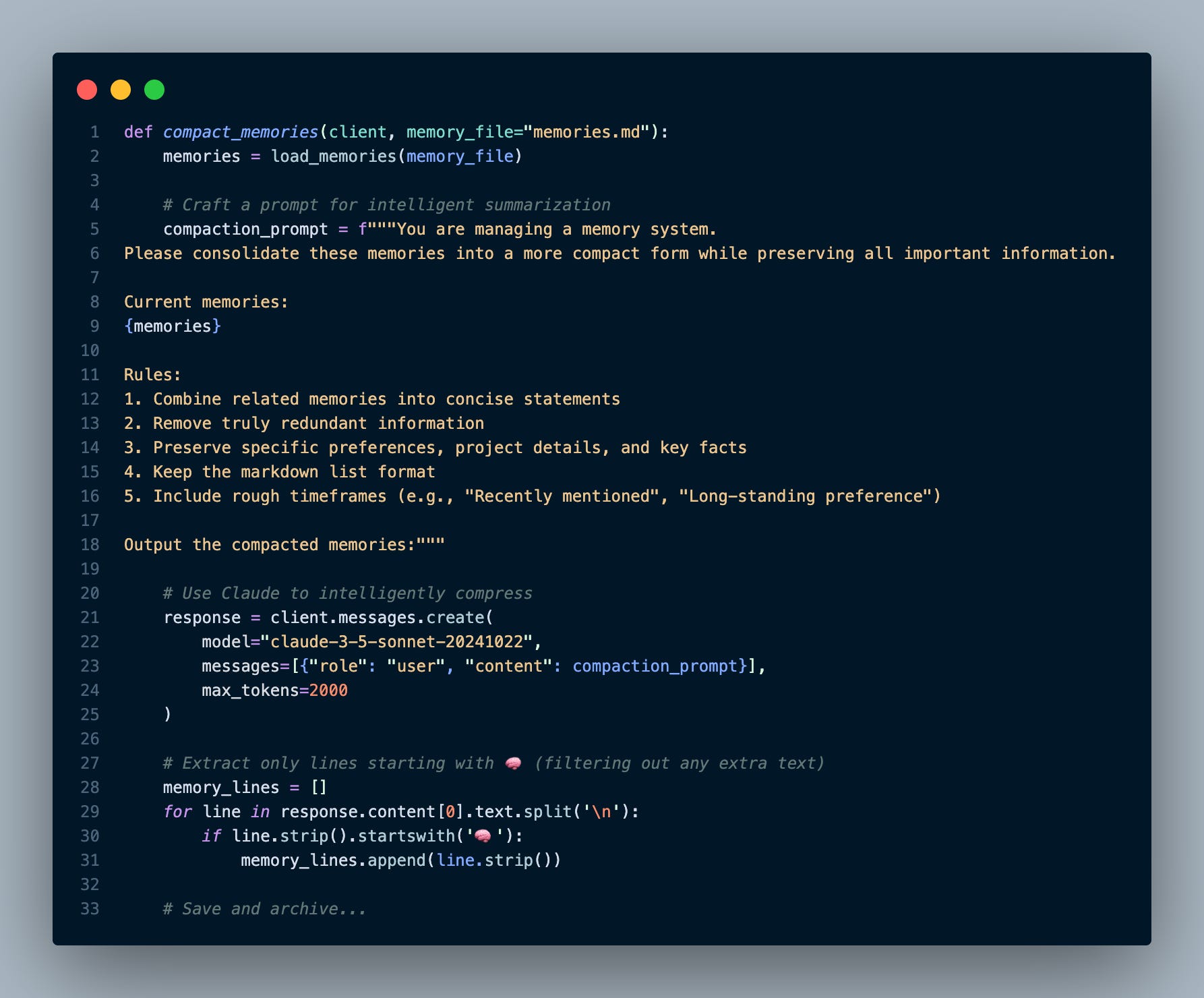
Here's what compaction does in practice:
Before compaction:
🧠 [2024-11-15 09:32] User prefers practical examples over theory
🧠 [2024-11-15 10:15] Doesn't like theoretical explanations
🧠 [2024-11-15 10:45] Working on a FastAPI project
🧠 [2024-11-15 10:46] Using PostgreSQL for the database
🧠 [2024-11-15 10:47] FastAPI project is a task management system
🧠 [2024-11-15 14:22] Likes concise explanations
🧠 [2024-11-15 14:23] Dislikes verbose responses
After compaction:
🧠 [Long-standing] Prefers practical examples and concise explanations,
dislikes theoretical or verbose content
🧠 [Current project] Building a FastAPI task management system with PostgreSQL
The companion app shows you the exact character reduction - often 70-80% while preserving all meaningful information. Your original memories are safely archived in a mem_archive folder with timestamps. A future extension of the app could add heuristics to leverage that memory archive.
With these simple mechanics, you transform one-off Q&A into an evolving partnership. Each !remember command builds context that makes future interactions more effective. The key insight: memory transforms stateless LLMs into stateful collaborators, one saved observation at a time.
When to Level Up
Let's be clear: this is a stripped-down example designed to demonstrate the core mechanism of LLM memory. We've intentionally kept it minimal to show you exactly what "memory" means. It's just text being included in the system prompt. No magic, no complex abstractions.
That said, a few extensions to this basic pattern might be all you need. Before reaching for an opaque third-party memory framework, consider extending what you've learned here. Add categories with !remember [work] prefixes. Implement keyword search when scrolling gets tedious. Create memory templates for consistent information capture. Each extension maintains the transparency of the original design.
When your needs outgrow files, the evolution is natural. SQLite gives you queries without complexity. Team systems might benefit from PostgreSQL or MongoDB for shared context. Vector databases and semantic search only make sense at scale, think thousands of memories where keyword matching genuinely falls short.
The beauty is that each option is just a different way to store and retrieve the same text. You understand the core mechanism, so you can choose storage based on actual needs, not architectural FOMO. Whatever you build, implement simple quality checks—compare responses with and without memories, track which memories get used, measure if your AI actually improves over time. This evaluation loop (worth its own exploration in a future post) ensures your memory system adds value rather than noise.
Start Building Today
Clone our companion app and experiment this week. Start with Level 1 - you'll have a working memory system in under an hour, and you'll be surprised how far simple files can take you.
The real win isn't our specific implementation. It's that you now understand what happens when an LLM "remembers" something. No more black boxes. No more wondering if you need that complex memory framework. You can build exactly what you need, starting with 20 lines of code.
Memory in AI isn't complicated. It's just text, thoughtfully managed. Now go build something that remembers.
Context Rot - How Increasing Input Tokens Impacts LLM Performance: https://research.trychroma.com/context-rot
OpenAI Memory Documentation - Official FAQ explaining how ChatGPT saves and uses information from conversations: https://help.openai.com/en/articles/8590148-memory-in-chatgpt-faq
Complete implementation with setup instructions: github.com/alteredcraft/simple-llm-memory