
Weekly review: Oxide’s LLM Integration Principles for Engineering Teams, O’Reilly: Two Futures for AI in 2026 and Beyond & much more
The week's curated set of relevant AI Tutorials, Tools, and News

Welcome back to Altered Craft’s weekly AI review for developers. This week’s theme is discipline over brute force: from Oxide’s principled LLM integration framework to research showing smaller context windows outperform bloated ones. On the infrastructure side, the Linux Foundation launched the Agentic AI Foundation with open standards such as MCP and AGENTS.md, signaling these are ready for production investment. You’ll also find GPT-5.2’s new reasoning controls, Mistral’s open-source coding agent, and MIT research on orchestrating small models for frontier-level results.
TUTORIALS & CASE STUDIES
Oxide’s LLM Integration Principles for Engineering Teams
Estimated read time: 8 min
Oxide Computer’s RFD 576 codifies a values-driven framework for integrating LLMs into engineering practice[1]. The document emphasizes human accountability over automation, endorsing research acceleration and debugging assistance while discouraging LLM-generated prose. Key principle: “human judgment remains firmly in the loop.”
Why this matters: A rare example of a respected engineering org publicly documenting their AI integration philosophy. Useful as a template for teams developing their own guidelines.
[1]: Complements last week’s 75/25 planning rule—both emphasize human oversight over automation.
Why 200K Token Context Windows Are Often Counterproductive
Estimated read time: 5 min

Applying similar discipline to context management, Lewis Metcalf argues that AI agents perform worse with bloated context[2]. “they get drunk if you feed them too many tokens.” His short-thread workflow methodology demonstrates 13+ interconnected threads for a single feature, improving performance and reducing costs.
The takeaway: Counterintuitive but practical. Smaller, focused conversations consistently outperform stuffing everything into one massive context window.
[2]: Extends last week’s Google context engineering framework with practical implementation patterns.
Reverse Engineering ChatGPT’s Memory Architecture
Estimated read time: 6 min
Shifting from principles to understanding existing systems, this analysis reveals ChatGPT’s four-layer context structure: ephemeral session metadata, long-term user memory, lightweight conversation summaries, and sliding-window messages. Key finding: OpenAI uses pre-computed summaries rather than traditional RAG.
What’s interesting: Understanding how production AI systems handle memory provides concrete patterns for building your own context-aware applications.
Build a GitHub Wiki Agent with Claude Opus 4.5
Estimated read time: 8 min
And finally, from analysis to hands-on building, this DataCamp tutorial walks through creating an autonomous documentation agent using Claude Opus 4.5 and the Claude Agent SDK. The CLI tool analyzes repositories, generates wiki content, and commits to GitHub automatically.
The opportunity: Documentation is a perfect first agent project. Well defined scope, clear success criteria, and immediate practical value for your repos.

TOOLS
Mistral Releases Vibe: Open-Source CLI Coding Agent
Estimated read time: 4 min
Mistral AI released Vibe, an Apache 2.0 licensed CLI coding agent built with Python, Pydantic, and Rich/Textual[3]. Simon Willison highlights the well-organized prompt architecture with specialized markdown files for bash, file operations, and search-replace patterns.
Worth noting: The readable codebase doubles as a learning resource. Study how Mistral structures prompts and tool interactions for your own agent projects.
[3]: Following last week’s Mistral 3 model family release, demonstrating rapid ecosystem expansion.
Cursor Launches Browser Visual Editor for AI Development
Estimated read time: 3 min
Also in the AI coding tools space, Cursor’s new visual editor enables developers to manipulate web interfaces through drag-and-drop while AI agents apply changes to underlying code. Features include React prop testing, interactive style controls, and parallel agent execution.
What this enables: Frontend development moves toward describing intent rather than manually coding. Point at elements and describe what you want changed.
ADK-Rust: Modular Agent Framework for Rust Developers
Estimated read time: 5 min

For developers building their own agents, ADK-Rust’s Google Agent Development Kit arrives for Rust with flexible agent types and MCP integration. Features include workflow agents for deterministic pipelines and multi-agent systems with automatic task delegation.
Key point: Rust developers now have a first-class agent framework. Useful if you need the performance and safety guarantees Rust provides for production agent systems.
OpenAI Releases GPT-5.2 with Enhanced Agentic Capabilities
Estimated read time: 12 min
Frontier model release: OpenAI GPT-5.2 introduces significant improvements in reasoning control, tool calling, and context management. New features include granular reasoning effort levels (none through xhigh), custom tools with grammar constraints, and preambles for transparent tool usage.
Why now: The new reasoning effort parameter lets you tune the speed-vs-accuracy tradeoff per request—crucial for building responsive yet capable agent workflows.
Poetiq Breaks 50% Barrier on ARC-AGI-2 Benchmark
Estimated read time: 4 min
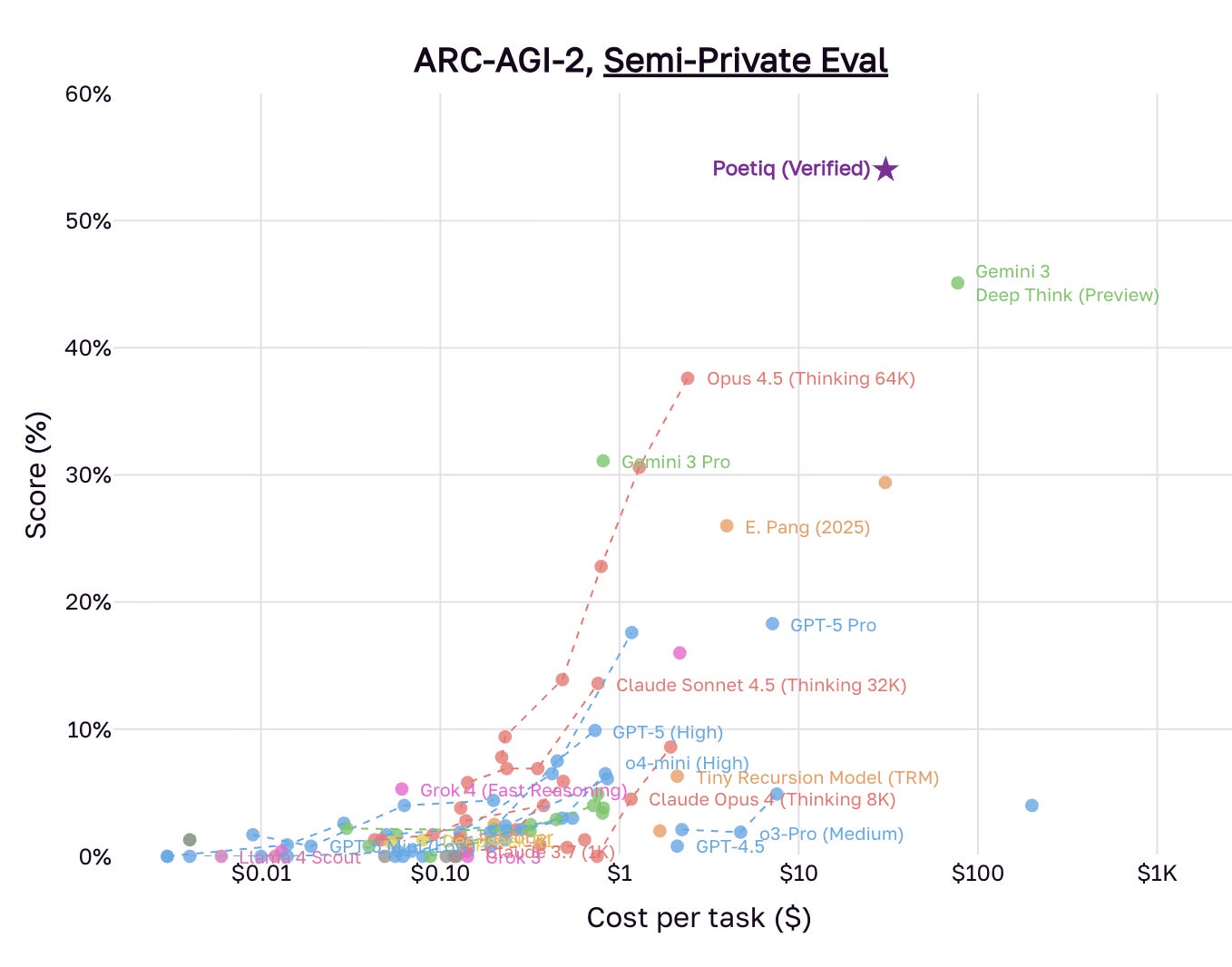
Demonstrating what’s achievable with optimized model orchestration, Poetiq achieved 54% accuracy on ARC-AGI-2 at half the cost of previous leaders. Rather than building proprietary models, their meta-system optimizes existing frontier models through learned test-time reasoning.
The context: System architecture beating raw model capability suggests that how you orchestrate models may matter more than which model you choose.
Netflix’s Unified Data Architecture: Model Once, Represent Everywhere
Estimated read time: 15 min

Shifting to data infrastructure, Netflix introduces UDA, a knowledge graph foundation for semantic data integration across content engineering. The architecture connects domain models to GraphQL, Data Mesh, and Iceberg through a unified metamodel enabling automatic schema generation.
Why this matters: As organizations scale AI-generated code and microservices, semantic consistency across systems becomes critical. Netflix’s approach offers a proven pattern, tested at the larget of scales.
Turbopuffer’s Vectorized MAXSCORE: 20x Faster Text Search
Estimated read time: 10 min
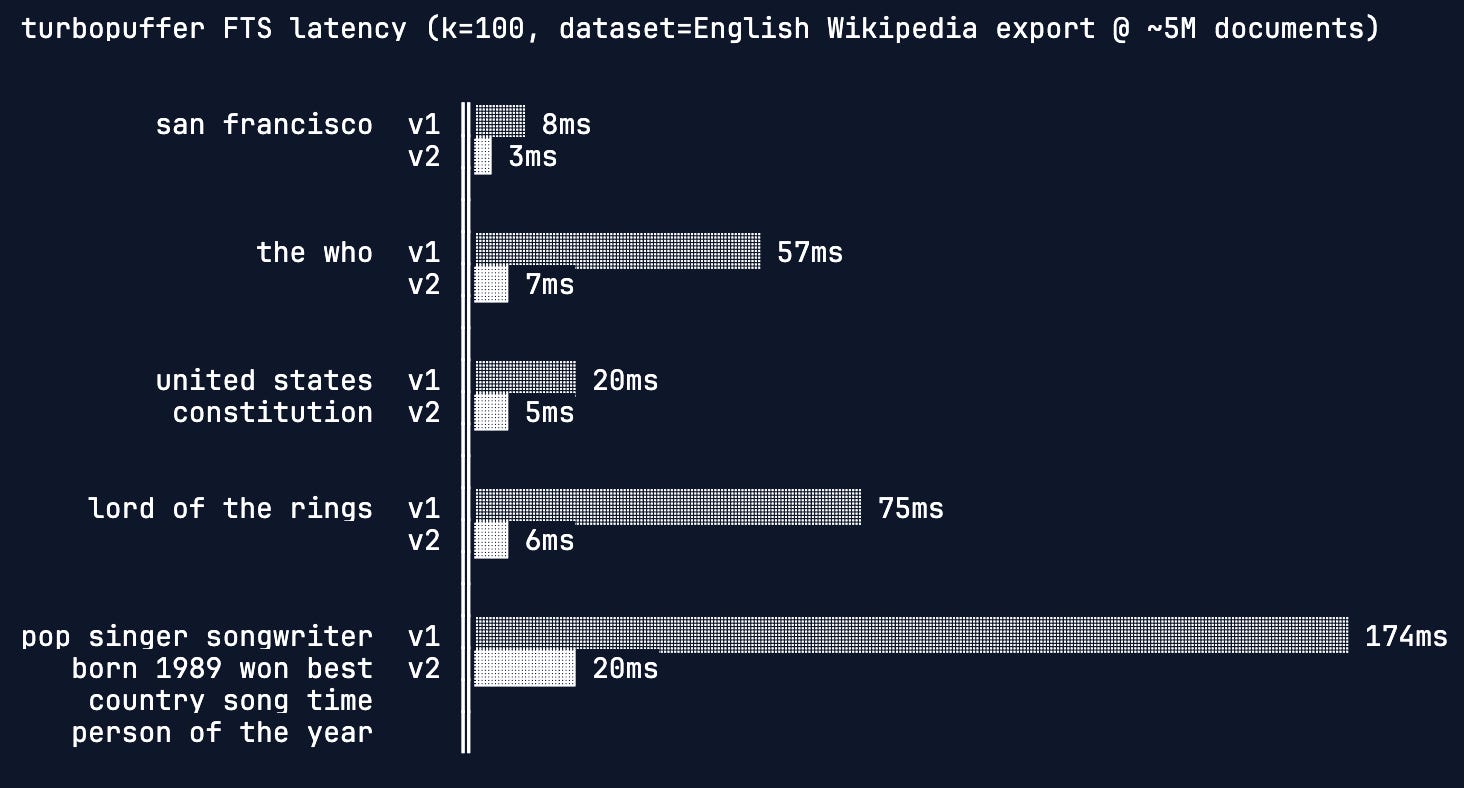
Also on the infrastructure front, Turbopuffer details their FTS v2 implementation using vectorized MAXSCORE over traditional WAND for full-text search. The approach achieves up to 20x faster search with dramatic speedups on longer LLM-generated queries.
What’s interesting: As AI agents generate longer, more complex queries, search algorithms optimized for traditional patterns need rethinking. This shows one path forward.
NEWS & EDITORIALS
Tim O’Brien: The End of Traditional Debugging
Estimated read time: 6 min
O’Reilly Radar explores how AI is shifting developers from writing and debugging to validating system behavior. O’Brien illustrates implementing features without reviewing implementation—relying purely on test results. Focus shifts to building systems machines can operate autonomously.
The takeaway: Testing and specification skills become more valuable as implementation details become AI-generated. A useful lens for thinking about where to invest your learning.
O’Reilly: Two Futures for AI in 2026 and Beyond
Estimated read time: 10 min
Expanding on these transformative themes, Tim O’Reilly and Mike Loukides examine whether AI represents an economic singularity or normal technology adoption. Practical guidance: focus on unit economics, build applications integrating unique data, and own direct customer relationships.
Worth noting: Rather than predicting one future, the authors suggest watching specific signals to guide strategy: company fundraising behavior, capability trajectories, enterprise deployment reality.
Meta Pivots from Open Source to Paid AI Model
Estimated read time: 5 min
Illustrating one response to these market pressures, Bloomberg reports Meta’s upcoming “Avocado” model may launch as closed-source with paid access—a significant departure from Meta’s open-source AI strategy. New Chief AI Officer Alexandr Wang advocates for closed models.
The context: Meta’s shift signals that open-source AI leadership may have limits when competing against well-funded closed alternatives.
Sourcegraph and Amp Split Into Independent Companies
Estimated read time: 5 min
In other strategic moves, Sourcegraph spins off Amp as a separate entity, recognizing their different distribution engines and target audiences. Sourcegraph focuses on enterprise code search; Amp pursues frontier coding agent capabilities.
Why this matters: Code search and AI agents serve different workflows. The split acknowledges that AI-generated codebases need both robust search infrastructure and cutting-edge agent tooling.
MIT’s DisCIPL: Small Models Solving Complex Reasoning Tasks
Estimated read time: 6 min
Shifting from industry news to research advances, MIT CSAIL researchers developed DisCIPL, enabling small language models to collaborate under large model direction. A GPT-4o planner coordinates multiple Llama-3.2-1B followers, achieving o1-level accuracy with 80% cost savings.
The opportunity: Parallelizing cheap small models under a smart coordinator opens possibilities for running sophisticated reasoning at dramatically lower cost.
Linux Foundation Launches Agentic AI Foundation
Estimated read time: 5 min
Providing governance for these emerging capabilities, the Linux Foundation announces AAIF with founding contributions from Anthropic, Block, and OpenAI including MCP, goose, and AGENTS.md. Over 10,000 MCP servers now exist; AGENTS.md adopted by 60,000+ projects.
Key point: MCP and AGENTS.md moving to neutral governance signals these standards are maturing—safe investments for building agent infrastructure today.
This breakdown of MIT's DisCIPL work is brilliant. The insight that a GPT-4o planner coordinating multiple Llama-3.2-1B models can match o1-level accuracy at 80% lower cost fundamentally changes how we think about deploying frontier capabilities. Instead of throwin huge models at every problem, orchestarting smaller specialists under smart coordination creates way more flexible and economical systems. I've been testing similar patterns with smaller models on domain-specific tasks, and the coordiation overhead is real but manageable if the planner understands task decomposition well.