
Weekly review: Building AI Agents From Scratch, Speech Recognition for 1,600+ Languages & much more
Edition #153 :: The week's curated set of relevant AI Tutorials, Tools, and News

Welcome to Altered Craft’s weekly AI review for developers. This week reveals a maturing industry: agent systems moving from prototype to production, model releases solving real reliability bottlenecks, and research showing exactly where current capabilities fail in practice. There’s also a reckoning with global infrastructure inequality that puts recent technical advances in sobering context.
Tutorials & Walkthroughs
Building AI Agents From Scratch Without Frameworks
Estimated read time: 5 min
This Node.js repository teaches developers to construct AI agents locally using LLMs without production frameworks. The progressive path covers system prompts, reasoning patterns, function calling, memory, and ReAct loops before reconstructing LangChain patterns from first principles.
Why this matters: Understanding agent internals helps you debug framework issues faster and customize behavior confidently when production tools don’t match your needs.
Google Jules: Asynchronous AI Coding Agent
Estimated read time: 3 min

Google Jules is an experimental coding agent operating asynchronously in cloud VMs with GitHub integration requiring code review. Three planning modes—Interactive, Review, or autonomous Plan and Go—offer real-time mini-diffs while Gemini-2.5-pro’s compiler/linter feedback loop improves results.
Kaggle AI Agents: From Prototype to Production
Estimated read time: 18 min
Beyond individual coding agents, Google’s comprehensive whitepaper addresses the operational lifecycle of AI agents, revealing 80% of effort goes to infrastructure, security, and validation—not intelligence. Built on Automated Evaluation, CI/CD, and Observability, it introduces Observe→Act→Evolve loops and Agent2Agent interoperability protocols.
Key point: If you’re moving agents beyond demos, this framework maps the production gap teams can underestimate when planning agent deployments.
Self-Evolving Agents: Automated Retraining Loops
Estimated read time: 6 min

Taking production operations further, OpenAI’s cookbook demonstrates how to build agentic systems that automatically improve through retraining loops, eliminating manual failure diagnosis. The framework uses versioned prompts, multi-grader evaluation, and GEPA optimization with separate validation datasets preventing overfitting.
What this enables: Agents can self-improve from production failures without engineering intervention, making long-term deployment viable for teams without dedicated ML operations staff.

Tools
Claude Structured Outputs: Guaranteed Schema Compliance
Estimated read time: 4 min
Anthropic released structured outputs for Claude on November 13, guaranteeing JSON schema compliance without parsing errors. Two modes: output_format for extraction/classification, strict: true for validated tool parameters. Python’s parse() transforms Pydantic models; TypeScript supports Zod schemas.
The opportunity: Eliminates retry logic and error handling for structured responses, simplifying agentic workflows where tool parameter validation has been a reliability bottleneck.
GPT-5.1: OpenAI’s Speed and Intelligence Balance
Estimated read time: 3 min
OpenAI released GPT-5.1 on November 12 with two variants: Instant for conversation quality and Thinking for reasoning that adapts to complexity. The suite including Codex variants rolls out in GitHub Copilot’s preview with API access via gpt-5.1 endpoints.
Claude Code Infrastructure: Production-Tested Patterns
Estimated read time: 4 min
Shifting from model releases to developer productivity, this reference library provides auto-activation systems solving Claude Code’s core problem: skills don’t activate automatically. Hook-based mechanisms analyze prompts and context to suggest relevant skills, following 500-line modular architecture with progressive disclosure.
DeepWiki: Conversational GitHub Documentation
Estimated read time: 2 min
DeepWiki generates interactive, AI-powered documentation for GitHub repositories, enabling conversational queries instead of static doc navigation. The platform indexes hundreds of major projects from React to Kubernetes, with Devin AI integration enabling private repository access.
What’s interesting: Treats documentation as a queryable interface rather than browsable content, matching how developers actually seek information when learning unfamiliar codebases.
Chandra: Open-Source OCR for Complex Documents
Estimated read time: 3 min
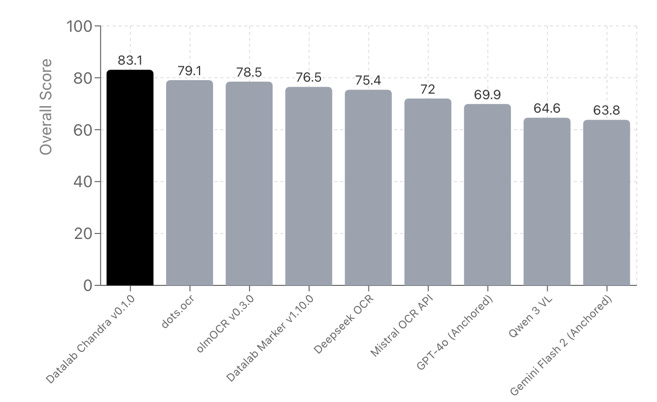
Chandra is an open-source OCR model converting images and PDFs into markdown, HTML, or JSON with preserved layout. It handles forms, math notation, handwriting, and complex tables across 40+ languages, achieving 83.1% benchmark performance with simple pip installation.
Omnilingual ASR: Speech Recognition for 1,600+ Languages
Estimated read time: 4 min
Meta’s open-source speech recognition system supports 1,600+ languages, including hundreds previously unsupported. Zero-shot learning enables new languages with minimal data, while model sizes (300M–7B parameters) balance real-time transcription and research needs with <10% error rates for 78% of languages.
Why this matters: Expands accessible speech interfaces beyond dominant languages, enabling voice applications for communities historically excluded from ASR technology advancement.
News & Editorials
McKinsey State of AI 2025: Scaling Challenges Persist
Estimated read time: 5 min
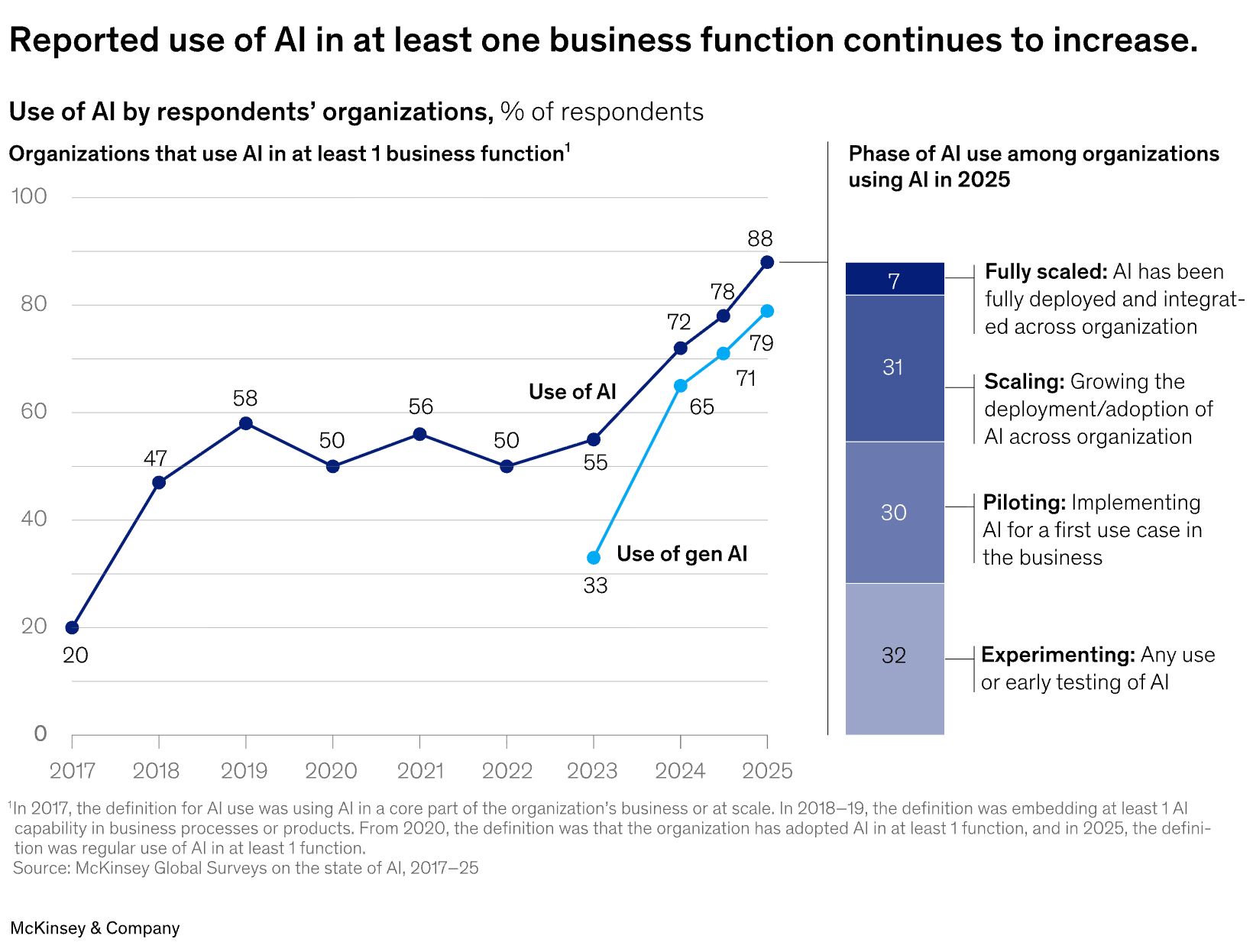
McKinsey’s Global Survey reveals 88% of organizations use AI regularly, yet only one-third scale beyond pilots. While 64% report innovation benefits and 23% deploy agentic systems, just 39% see EBIT impact. The top success factor: workflow redesign, not technology selection.
Microsoft AI Diffusion Report: Infrastructure Inequality
Estimated read time: 4 min

Microsoft’s AI Economy Institute analyzes global AI adoption disparities despite 1.2 billion users. U.S. and China control 86% of data center capacity; seven countries host frontier models. Barriers include electricity (750M people), connectivity (Zambia: 34% adoption among internet users), and language (Yoruba: 55% accuracy vs. English 80%).
The Hierarchy of Agentic Capabilities: Where Models Fail
Estimated read time: 5 min
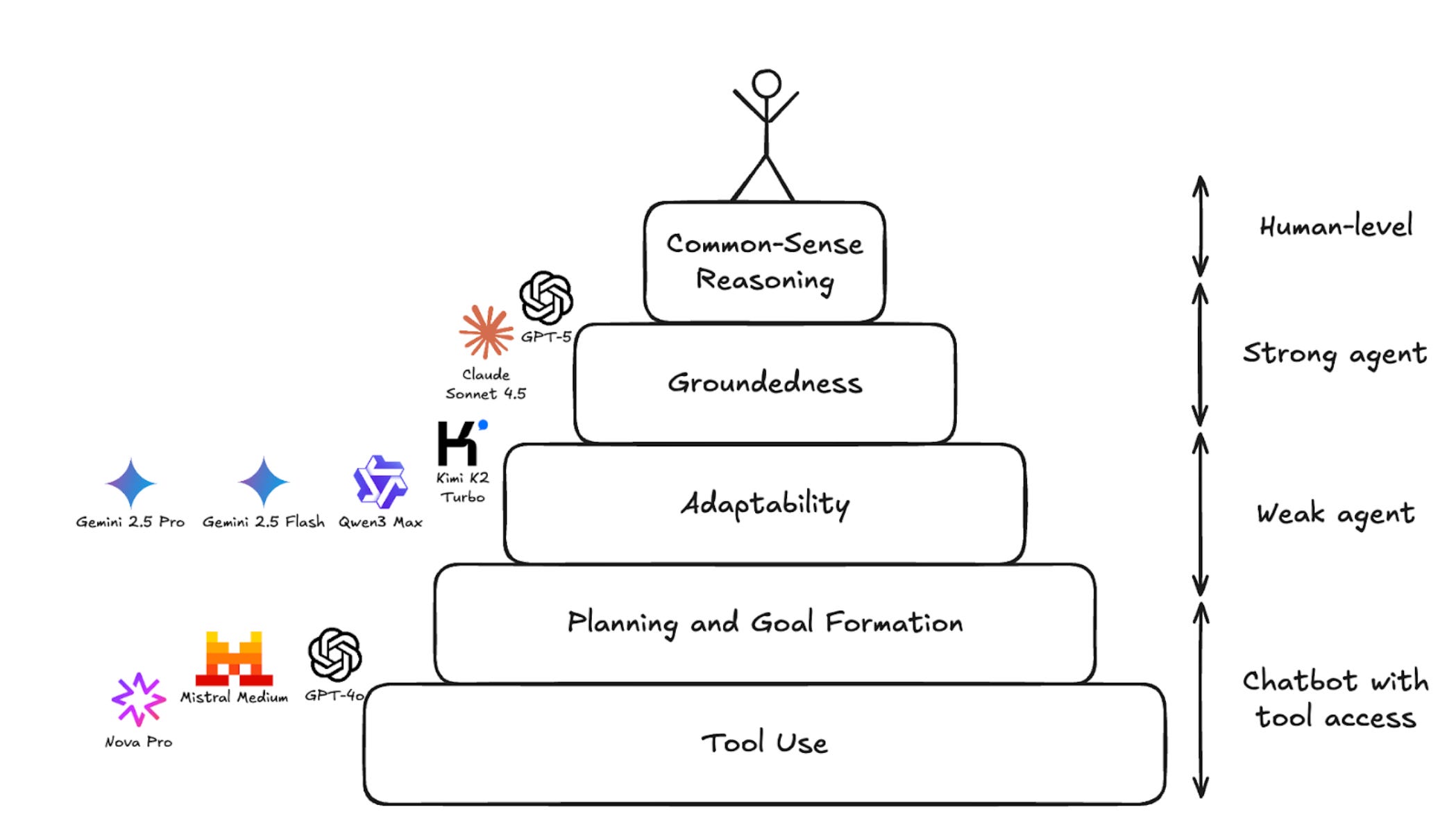
Surge AI evaluated nine frontier models on 150 real-world workplace tasks, revealing a four-level hierarchy. Basic tool use fails from parameter misuse; adaptability from missing retry strategies; groundedness from hallucinations. Common-sense reasoning remains hardest—GPT-5 and Claude fail >40% of agentic tasks.
Worth noting: Emphasize tool validation and alternative strategies in your agent designs; architectural innovations may matter more than waiting for model improvements.
Three Competing Visions for World Models
Estimated read time: 4 min
“World model” encompasses three fundamentally different technical approaches launched simultaneously. World Labs’ Marble creates navigable 3D scenes; DeepMind’s Genie 3 generates interactive video for agent training; LeCun’s JEPA learns compressed latent representations without rendering pixels.
What’s interesting: These aren’t competitors but complementary layers. Human visualization, agent training, and internal computation. Each with distinct applications and scalability trade-offs.
Why AI Struggles With Legacy Code
Estimated read time: 4 min
OpenHands chief architect Ray Myers argues LLM-based coding agents fundamentally mismatch legacy systems, which combine high risk, unclear context, limited tests, and lost knowledge. Myers advocates “goals first” thinking: leverage compilers for transformation, formal methods for verification, AI within constrained scopes.
This article arrives at an opportune moment, providing an incisive analysis of AI agent evolutoin and the crucial global infrastructure considerations.