
Weekly review: Are We In a Shift from Scaling to Research, OpenAI: Building Teams Where AI Handles Implementation & much more
Edition #155: The week's curated set of relevant AI Tutorials, Tools, and News

Welcome to Altered Craft’s weekly AI review for developers, and we’re grateful you’re here. This week, a thread connects nearly every piece we’ve collected: the industry is getting serious about making agents actually work. From Anthropic’s harness patterns to Phil Schmid’s mindset shifts to OpenAI’s team delegation framework, production reliability has moved from afterthought to central concern. We’ve also got Ilya Sutskever signaling a pivot from “the age of scaling” to “the age of research,” which pairs well with Helen Toner’s case for expecting uneven capabilities rather than smooth progress.
TUTORIALS & CASE STUDIES
Harnesses That Keep Long-Running Agents on Track
Estimated read time: 7 min
Building on our coverage of Armin Ronacher’s production agent patterns[1] from last week, Anthropic’s engineering team shares patterns for maintaining agent context across multiple sessions when context windows become limiting. The two-part architecture uses an initializer agent for infrastructure setup, then a coding agent that reads progress files and commits incrementally.
[1] Hard-Won Patterns for Building Production AI Agents
What this enables: If you’re building agents for multi-hour tasks, this architecture solves the context persistence problem that causes most long-running workflows to drift or stall.
Why Traditional Engineering Habits Break Agent Development
Estimated read time: 5 min

These reliability challenges often stem from a deeper issue: Phil Schmid identifies five ways deterministic engineering mindsets clash with probabilistic AI agents. Key shifts: preserve full text as state instead of binary fields, feed errors back as inputs rather than crashing, and use evaluations measuring reliability (Pass^k rate) instead of traditional unit tests.
The takeaway: Understanding these mental model shifts early saves significant debugging time—most agent failures trace back to forcing deterministic patterns onto probabilistic systems.
Three Beta Features for Smarter Tool Integration
Estimated read time: 8 min

Once you’ve embraced the probabilistic mindset, tool orchestration becomes the next challenge. Anthropic introduces three advanced tool use features that dramatically reduce token consumption. Tool search enables dynamic discovery (reducing 72K tokens to 8.7K), programmatic tool calling orchestrates workflows through code, and tool use examples teach proper parameter conventions.
Why this matters: These patterns directly address the cost and complexity barriers that have made production tool-heavy agents impractical for many teams.
Building Teams Where AI Handles Implementation
Estimated read time: 7 min
Taking tool orchestration to the team level, OpenAI’s guide presents a structured framework for delegating routine work to agents across the SDLC. Engineers shift from implementation to review—agents generate features while humans own architectural decisions. The core principle: delegate routine work, review outputs, own strategy.
Worth noting: This isn’t theoretical, it reflects how frontier AI teams are actually restructuring engineering workflows, with clear guidance on where human judgment remains essential.
Building Local RAG with Practical Component Choices
Estimated read time: 6 min
Shifting from agent orchestration to retrieval systems, this hands-on guide walks through building a local RAG system with tested component recommendations: Postgres with pgvector, all-MiniLM-L6-v2 for embeddings, and Sentence Transformers for reranking.
The opportunity: Practical guidance for teams exploring local RAG before committing to cloud APIs—useful for privacy-sensitive use cases or cost optimization.

TOOLS
Claude Opus 4.5 Delivers State-of-the-Art Coding Performance
Estimated read time: 4 min

Anthropic releases Claude Opus 4.5, achieving top scores on SWE-bench Verified while using 76% fewer output tokens at medium effort levels. New features include effort control for balancing capability with cost, extended conversations, and enhanced multi-agent coordination at $5/$25 per million tokens.
Key point: The efficiency gains matter as much as the capability improvements. 76% fewer tokens means significantly lower costs for high-volume agent workflows.
Plugin Transforms Each Engineering Task Into Future Leverage
Estimated read time: 5 min
For Claude Code users, the Compounding Engineering Plugin embodies systematic development that makes subsequent work easier. Three commands: Plan generates comprehensive GitHub issues, Work executes via isolated worktrees with quality checks, and Review performs multi-agent analysis with 12+ specialized agents for security and architecture.
What’s interesting: The philosophy of “compounding engineering” & each task should reduce friction for future tasks, pairs well with agentic workflows that benefit from accumulated context.
30 Pro Tips for Terminal-Based AI Development
Estimated read time: 6 min
Also in the AI coding assistant space, Addy Osmani compiles practical techniques for Gemini CLI covering context management and advanced workflows. Highlights include GEMINI.md files for persistent context, MCP server extensions, Google Workspace integrations, and checkpointing for instant rollback.
Why now: As terminal-based AI assistants mature, the gap between casual and power users is widening. These tips help you get meaningfully more from tools you’re already using.
Open-Source Agent Framework Handles 600 Tool Calls Per Task
Estimated read time: 5 min

For those building their own agent infrastructure, MiroThinker introduces open-source agentic models trained for deep research with “interactive scaling.” The framework supports 256K context windows and up to 600 tool calls per task across 8B, 30B, and 72B parameter variants.
The context: Open-source agent frameworks are catching up to proprietary offerings. 600 tool calls per task opens up research and monitoring workflows previously limited to closed systems.
FLUX.2 Brings Production-Grade Image Generation
Estimated read time: 4 min
Moving from code to visuals, Black Forest Labs releases FLUX.2 with multi-reference support allowing up to 10 simultaneous reference images for character and style consistency. Key improvements include reliable text rendering for UI mockups and enhanced prompt adherence for complex instructions.
What this enables: Multi-reference consistency finally works reliably enough for production design workflows. Useful for maintaining brand identity across generated assets.
NEWS & EDITORIALS
Eight Benchmarks Defining Real-World Agent Capability
Estimated read time: 6 min
This analysis surveys emerging benchmarks that measure what agents actually accomplish rather than raw model capability. From SWE-Bench’s GitHub issue resolution to Terminal-Bench’s command-line workflows, these evaluations address the reality that agents fail from missing context, not lack of intelligence.
Why this matters: Understanding these benchmarks helps you evaluate agent capabilities more critically. They identify which metrics actually predict production performance for your use cases.
Why AI Capabilities Will Stay Uneven Rather Than Smoothly Advancing
Estimated read time: 8 min
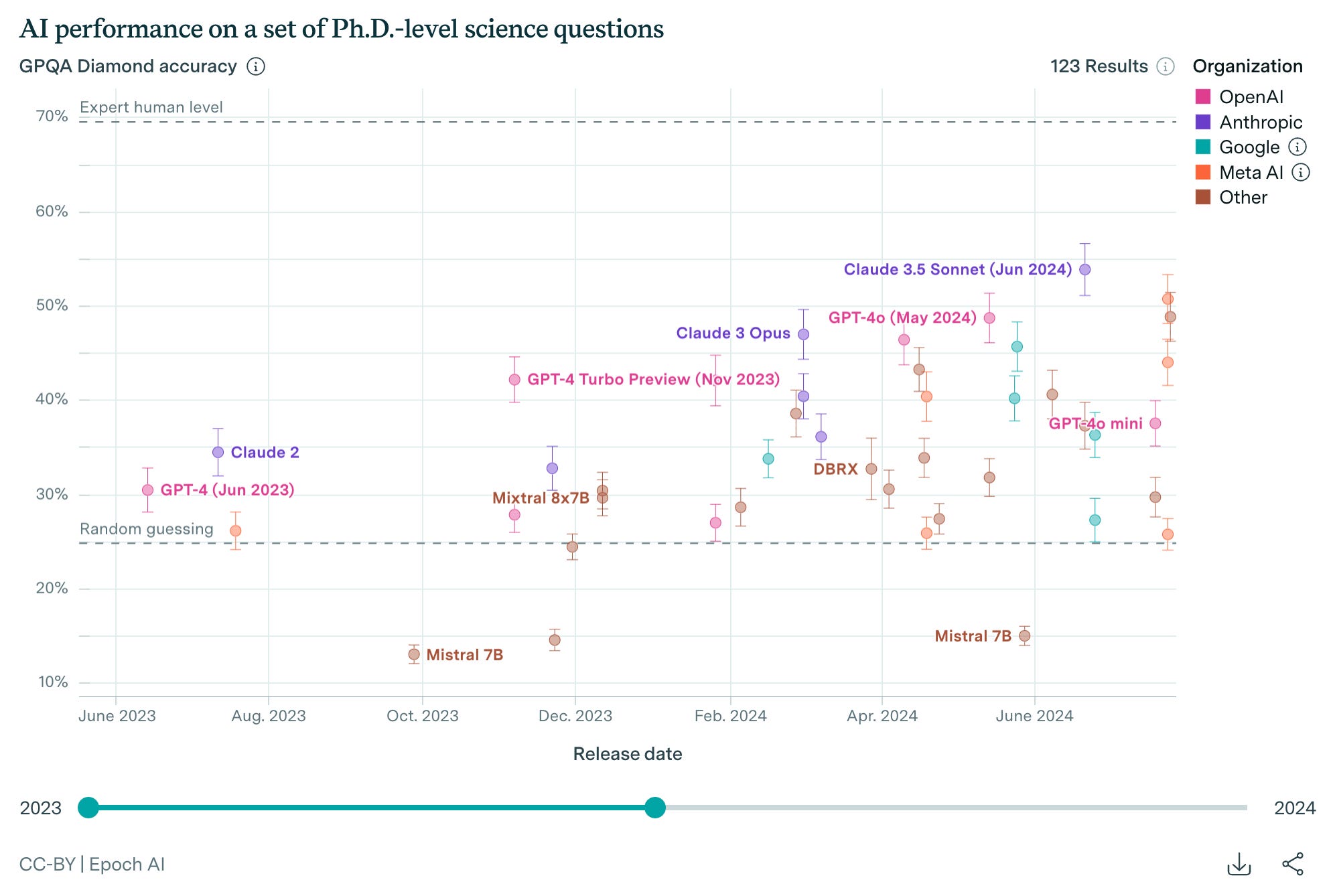
These benchmarks reveal an important pattern: Helen Toner argues developers should expect continued jaggedness in AI capabilities where impressive performance coexists with surprising basic failures. Tasks with clear reward signals advance faster than those requiring subjective judgment.
The takeaway: Planning for uneven capabilities rather than waiting for universal competence leads to more resilient architectures. Design for human-AI collaboration, not eventual full automation.
Ilya Sutskever on the Shift from Scaling to Research
Watch time: 93 min
In this Dwarkesh Patel interview, OpenAI co-founder Ilya Sutskever discusses SSI’s strategy and the limits of pre-training. Key themes include model jaggedness, why humans generalize better than models, and what it means to be “squarely a research company” focused on understanding rather than scaling.
Worth noting: When one of the architects of the scaling era signals a strategic pivot toward research fundamentals, it’s worth understanding the reasoning behind the shift.
AI’s Unsustainable Economics Mirror Uber’s Early Days
Estimated read time: 7 min
While researchers debate capability trajectories, the business models remain uncertain. This analysis exposes the structural economics problem where AI costs scale linearly with usage. Unlike Netflix where content serves millions at low incremental cost. Services like GitHub Copilot may sell $12 of compute for $10/month.
The context: Understanding these economics helps you anticipate pricing changes and architect systems that remain cost-effective as subsidies eventually normalize.
AI Safety Regulations Pose Negligible Competitive Threat
Estimated read time: 10 min
Amid these economic pressures, policy debates continue. Scott Alexander argues AI safety measures cost roughly 1% of training expenses. Far smaller than other policy decisions affecting US-China competition. The real vulnerability: chip exports could collapse America’s 10-30x compute advantage to 2x.
Key point: A data-driven reframe of a heated debate. Useful context for conversations about regulation’s actual impact versus the rhetoric surrounding it.