
Testing Mozilla's any-llm: A Practical Take on Provider Abstraction

Note to my readers: this is new format I’m testing for analysis based posts, more of a “learning in public format.” Let me know if it’s valuable. I’ll still be posting longer form content and the Weekly AI Roundups.
I spent today exploring Mozilla’s any-llm library. While it’s part o
f the larger mozilla.ai agent platform, the library stands alone perfectly well.
Why Provider Abstraction Matters Now
The library offers unified interfaces for Completions and Responses across LLM providers. It also standardizes error handling with custom exceptions for common issues like missing API keys or unsupported parameters. There are additional features such as a proxy gateway which you can read about that in their docs
LLM provider abstraction matters because the frontier model landscape is shifting rapidly. For instance Kimi’s K2 Thinking model just outranked incumbents on key benchmarks last week. With providers competing on performance, speed, and pricing, switching models when a cheaper and/or faster alternative meets your needs becomes a real advantage.
Building a Test Harness
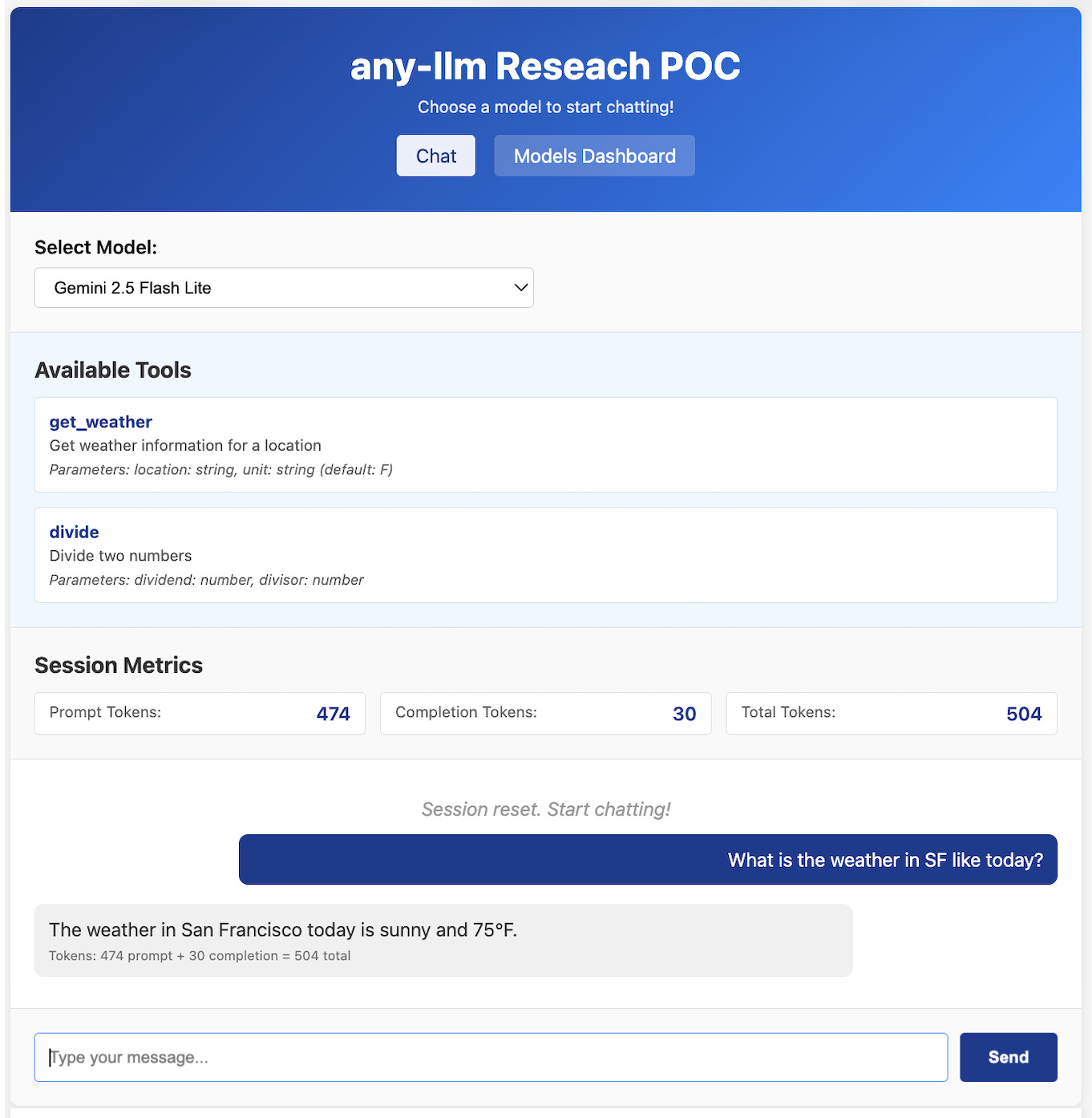
I built a functional research POC (available on GitHub) with a simple web UI for switching between configured providers and models. My analysis focused on two questions:
Does the abstraction add meaningful complexity?
How does it handle feature disparities between models?
The Complexity Question
Does the use of Any-llm add complexity to your code? The quick answer: no. Any-llm’s interface matches the complexity of native provider APIs. You write the same code, but it works across providers. The reverse is actually true. The use of Any-llm will reduce the amount of code you write. They maintain the adapter boilerplate so you don’t have to.
# The main chat loop for my POC
@app.post(”/api/chat”, response_model=ChatResponse)
async def chat(request: ChatRequest):
“”“Handle chat completion requests with tool support”“”
try:
# Convert Pydantic Message models to dicts for any-llm
messages = [{”role”: msg.role, “content”: msg.content} for msg in request.messages]
# Build acompletion kwargs based on tools_support
completion_kwargs = {
“provider”: request.provider,
“model”: request.model,
“messages”: messages,
“max_tokens”: 2048,
“stream”: False, # Disable streaming to get complete response object
}
# Only add tools if the model supports them
if request.tools_support:
completion_kwargs[”tools”] = list(TOOL_FUNCTIONS.values())
# Call any-llm SDK with conditional tool support
response = await acompletion(**completion_kwargs)
# Extract response and token usage
message = response.choices[0].message
content = message.content
usage = response.usage
# Extract tokens from initial response
tokens = _extract_tokens(usage)
# Handle tool calls - execute tools and get final response
if message.tool_calls:
content, tokens = await _handle_tool_calls(
message, messages, completion_kwargs, tokens
)
return ChatResponse(
response=content,
prompt_tokens=tokens[’prompt_tokens’],
completion_tokens=tokens[’completion_tokens’],
total_tokens=tokens[’total_tokens’],
)
except {truncated for brevity}
The Feature Delta Problem
In the above code example you may have noticed this line, if request.tools_support:. This is an example of the effort needed to maintain one code base against multiple API providers. Without this check, if we were to send a call to llama3 with a list of available tools, we would see this response:
2025-11-12 16:15:55,488 - app - ERROR - Chat completion failed - model: ollama:llama3:latest, error: registry.ollama.ai/library/llama3:latest does not support tools (status code: 400)
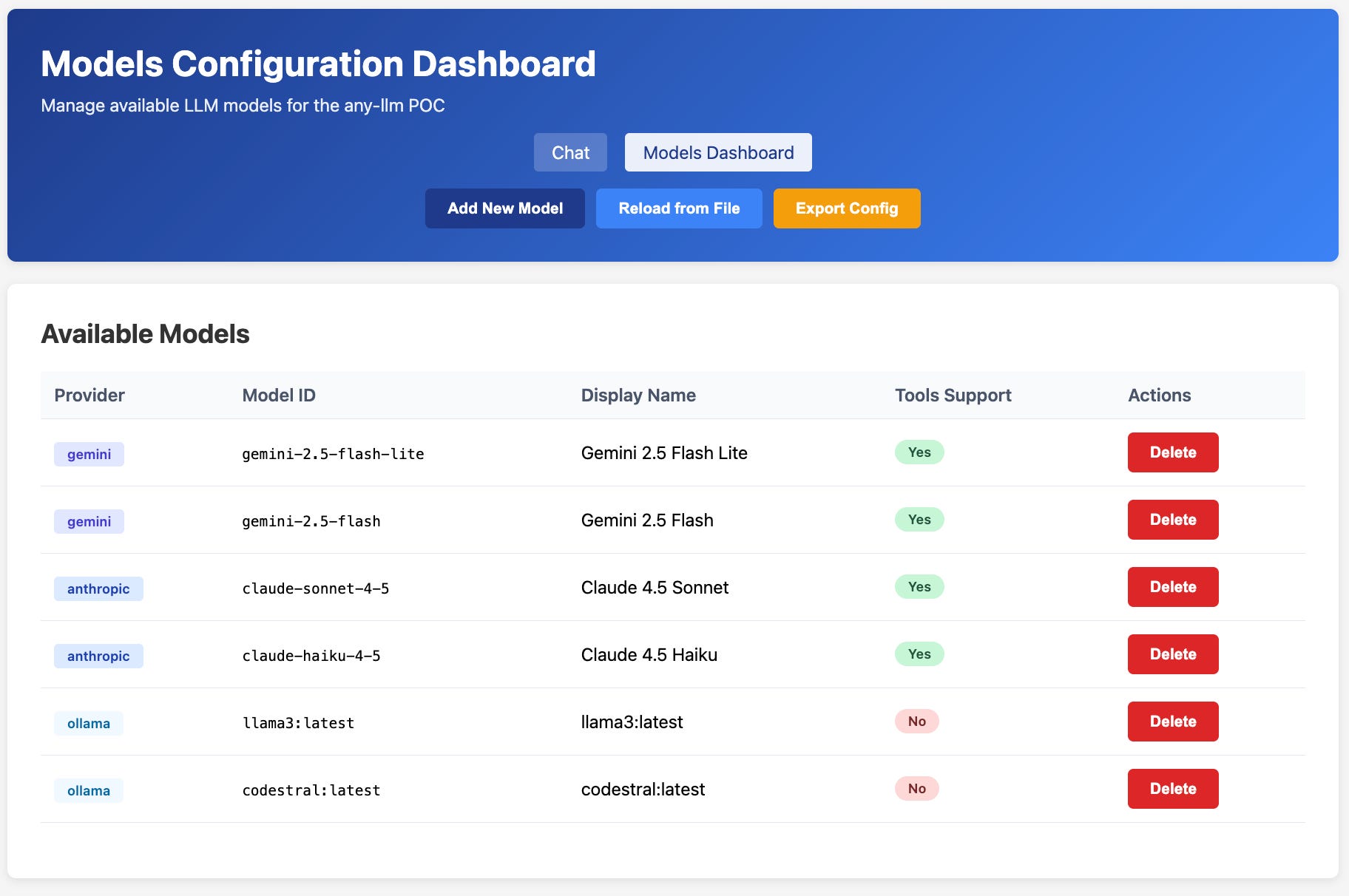
Any-llm does give us the benefit of catching the native provider exceptions and returns standardized ones. Helpful, but you still need to track capabilities for provider models yourself:
AVAILABLE_MODELS = [
{
“provider”: “gemini”,
“model”: “gemini-2.5-flash-lite”,
“display”: “Gemini 2.5 Flash Lite”,
“tools_support”: True
},
{
“provider”: “ollama”,
“model”: “llama3:latest”,
“display”: “llama3:latest”,
“tools_support”: False
},
# ...
]
Then build your completion calls conditionally:
completion_kwargs = {
“provider”: request.provider,
“model”: request.model,
“messages”: [{”role”: “user”, “content”: request.message}],
“max_tokens”: 2048,
}
# Only add tools if the model supports them
if request.tools_support:
completion_kwargs[”tools”] = [get_weather, divide]
response = await acompletion(**completion_kwargs)
This seems reasonable. Model capabilities are static per version. For example you’ll never see gemini-2.5-flash-lite gains new features, they’ll arrive in gemini-2.6-flash-lite.
So you’ll build this provider/model registry once and you’re set.
Conclusion: The Build vs. Adopt Decision
If you’re working with just a few models, implementing your own adapter might make sense. If integration with an LLM API is in the critical path for your product, adding another 3rd party abstraction over said API can bring appreciable risk. Check the bug resolution history to gauge your comfort level. This is classic Gang of Four Adapter/Facade territory, and crafting abstractions tuned to your team’s needs can be satisfying work.
For R&D scenarios outside the critical path, a library like this shines. When your goal is testing many models quickly rather than production stability, the abstraction pays dividends.
Bottom Line
Mozilla’s any-llm delivers on its promise of unified interfaces and error handling. The feature delta problem requires manual tracking, but that’s inherent to the current LLM landscape, not a library failing. For teams experimenting with multiple providers or preparing for rapid model switching, it’s worth serious consideration.
Have you built your own provider abstraction layer? What patterns worked (or didn’t) for your team? Drop a comment or reach out on LinkedIn - I’d love to compare notes on handling the feature delta problem.