
Agent Native Architecture
Calibrating Autonomy and Predictability in Agent Systems

Abstract
This paper introduces Agent Native Architecture (ANA), a software design paradigm where an AI agent serves as the reasoning core of an application, with data structure emerging at runtime through the agent’s understanding rather than being predetermined at design time. ANA represents an evolution beyond AI-enhanced and AI-first approaches, inverting the traditional relationship between schema and understanding: structured data becomes an output of reasoning, not an input required from users or hardcoded by developers. The paper defines the core requirements for ANA, including a determinism model that places orchestration in the agent while tools provide predictable operations. The paper introduces the determinism spectrum as a key design dimension. A companion implementation explores these concepts through one point on this spectrum: a personal assistant that pushes toward high agent autonomy.
1. Introduction
The integration of large language models (LLMs) into software applications has followed a predictable pattern: take an existing application architecture, identify features that could benefit from language understanding, and add AI capabilities as an enhancement layer. This AI-enhanced approach treats the LLM as a sophisticated feature rather than a foundational component.
A more recent pattern, AI-first design, centers the application around AI capabilities from inception. However, even AI-first applications typically maintain traditional strict schema-driven architectures. The data model is defined at design time; the AI operates within those structural constraints. Some applications are beginning to blur these boundaries. Jottie, for example, extracts due dates and shifts classification from tag to entity as users type, without explicit field entry. I have no insight into Jottie’s backend implementation but suspect it exhibits some ANA properties.
This paper proposes a further evolution: Agent Native Architecture, where the LLM agent is not merely central but generative of structure itself. The schema emerges from the agent’s reasoning at runtime, rather than being predetermined by developers. Concurrent work by Shipper [4] explores similar territory from production experience—top-down learning from shipping products. This paper takes a complementary bottom-up approach. I highly recommend reading Dan’s post as well; different perspectives surface different insights, but encouragingly I noticed some convergence on key principles.
The paper proceeds as follows: I define ANA’s core requirements (Section 3), introduce a determinism model explaining where predictability lives in the system (Section 4), and map the design space architects must navigate (Section 5). I then examine capabilities and tradeoffs (Sections 6-7) before exploring a concrete implementation (Section 8). The contribution is the architectural framework; the application illustrates rather than defines it.
1.1 The Fundamental Inversion
Traditional applications are schema-first: developers define data models, build features around them, then optionally add AI. The schema dictates what the application can understand and express.
Agent Native applications are semantic-first: the agent’s understanding of language and context is the core. Structured data becomes an output of reasoning, not an input required from users.

Consider a task management application. In traditional design, a Task model defines required fields: title, due_date, project_id, priority. Users must translate their intentions into this structure. In an agent-native design, the user says “remind me to call Mom before my flight tomorrow,” and the agent produces appropriate structure: a task linked to a calendar event, with temporal context. The user never needs to understand or manipulate the underlying schema.
This inversion has cascading implications for interface design, workflow flexibility, and emergent capabilities. Section 6 explores these in detail.
2. Defining “Agent”
The term “agent” is overloaded in both AI and software engineering contexts. An agent can be defined as anything that perceives its environment and acts upon it, characterized by its operational domain and available tools [1]. For the purposes of Agent Native Architecture, I define an agent by three necessary properties:
PropertyDescriptionGoal-directed reasoningPursues objectives through multi-step planning, not merely responding to promptsTool useAffects the world through actions, not just generates textPersistenceMaintains state across interactions
These properties distinguish agents from adjacent concepts:
A stateless LLM call (inference) lacks all three properties
A chatbot with conversation history has persistence but typically lacks goal-direction and tool use
A workflow/pipeline with LLM steps may use tools but lacks autonomous reasoning. The orchestration is predetermined.
An agent combines goal-directed reasoning with the ability to affect state through tools, while maintaining memory across interactions. For short-running agents, persistence may be achieved through the context window alone; long-running agents require external memory mechanisms.
The term “Agent Native” therefore implies an architecture that supports goal-directed, tool-using, persistent behavior as a foundational capability, not an optional feature.
3. Core Requirements
For an architecture to qualify as Agent Native, three requirements must be satisfied:
3.1 LLM as Reasoning Core
The agent is the decision-making engine, not a feature layered onto existing logic. User intentions flow through the agent’s understanding before being translated into structured operations. This distinguishes ANA from AI-enhanced approaches where the LLM handles specific features (autocomplete, summarization, search) while traditional code handles core logic.
3.2 Runtime Schema Emergence
Structure is determined during execution, not fixed at design time. The agent decides what properties are relevant for a given item, what relationships exist between items, and how information should be organized. This does not mean the absence of schema. Rather, it means the agent participates in schema definition.
In practice, this manifests through flexible primitives. Rather than create_task(title, due_date, project_id), the agent operates with create_item(content, properties) where properties are open-ended. The generic term “item” is intentional; it carries no domain semantics. The agent decides whether this item is a task, note, reminder, or something else entirely.
3.3 Global Awareness
Agents require persistence across interactions to learn user patterns, maintain context, and improve over time. For agents operating across multiple sessions, this presents an architectural challenge: each new session starts fresh. The LLM receives the system prompt and the current conversation, but has no memory of prior interactions.
The system prompt is developer-controlled. It defines the agent’s persona: “You are a personal assistant that helps manage tasks and priorities.” But the system prompt cannot encode user-specific knowledge. It applies to all users equally.
ANA requires a mechanism for user-specific adaptation beyond the system prompt. The agent must accumulate knowledge about this particular user, including their preferences, patterns, constraints, and working context. This knowledge must shape reasoning in every session.
A naive approach stores everything in a retrievable memory system (RAG). The agent queries memory when relevant, surfacing past context. This works for episodic information (”what did I decide about the Q3 timeline?”) but fails for foundational preferences.
Consider: the user once mentioned “I prefer deep work in mornings.” With retrieval-based memory, this preference surfaces only when semantic search happens to find it relevant. The agent planning tomorrow’s schedule might not retrieve it. The agent suggesting a 9am meeting might not retrieve it. The preference exists in storage but doesn’t consistently shape reasoning.
The architectural insight: some knowledge must be constitutive of reasoning, always present and shaping every interaction. User preferences like “never schedule meetings on Fridays” need to inform planning consistently, not probabilistically. This knowledge belongs alongside the system prompt, present at the start of every session, not discovered through retrieval.

How this is implemented varies. The requirement is the capability: the agent must be globally aware of user-specific context that evolves over time, with foundational knowledge always present rather than retrieved. This insight emerged from my earlier work on implicit memory systems [3], where delegating memory decisions to the LLM revealed that contextual intelligence could replace programmed rules.
4. The Determinism Model
ANA introduces a specific model for where determinism lives in the system. This model inverts traditional software architecture.
Traditional software: Code provides deterministic orchestration. Given state X and input Y, the execution path is predetermined. The developer specifies: “if user clicks submit, validate fields, then save to database, then show confirmation.” Data is the variable; logic is fixed.
Agent Native: Tools provide deterministic operations. Given a tool call with specific parameters, the result is predictable. But which tools get called, in what order, with what parameters is determined by the agent’s reasoning. Orchestration is the variable; operations are fixed.

Two distinct properties are at play:
Determinism is a property of the system: how predictable are outcomes given inputs?
Agent autonomy is a property of the agent: how much does the agent decide versus following predetermined paths?
Higher agent autonomy tends to reduce system determinism. This is not inherently good or bad. It creates risk, which may be acceptable or unacceptable depending on the domain. The architect’s role is to calibrate this risk.
Tools are the primary lever for adding determinism. A tool that enforces validation, requires confirmation, or constrains options adds predictability. The agent cannot circumvent what tools enforce. An ANA with no tools is just a stateless chatbot; tools are what make agents useful and what give architects control over system behavior.
System prompts also influence behavior, but with a softer guarantee. A prompt can instruct “always confirm before deleting,” and modern models follow such instructions somewhat reliably, but not absolutely—even frontier models achieve only around 80% accuracy on simple, unambiguous instructions [2]. Tools enforce; prompts guide. Section 5 explores how these surfaces combine.
This model explains why ANA is not “non-deterministic chaos” (see Section 7.1): every tool call is logged and traceable. System operators can observe what the agent did, audit decision patterns, and identify opportunities to improve. You gain adaptive capability by accepting that orchestration emerges from reasoning, but you retain visibility into that reasoning through tool-level observability.
5. The Determinism Spectrum
Section 4 established that tools provide hard determinism (guaranteed behavior) while prompts provide soft influence (reliable but not absolute). This section explores how these surfaces combine and how architects can position their systems along the determinism spectrum.
5.1 Influence Surfaces
Two primary surfaces shape agent behavior:
SurfaceNatureHigh ConstraintLow ConstraintToolsHard determinism: agent cannot circumventcreate_task(title, due_date, project)create_item(content, properties)Prompt GuidanceSoft influence: agent follows reliably but not absolutely”Tasks must have priorities 1-4” + rigid few-shot examples”Items can have any properties you find useful” + flexible examples
5.2 The Design Space
These surfaces create a two-dimensional design space:
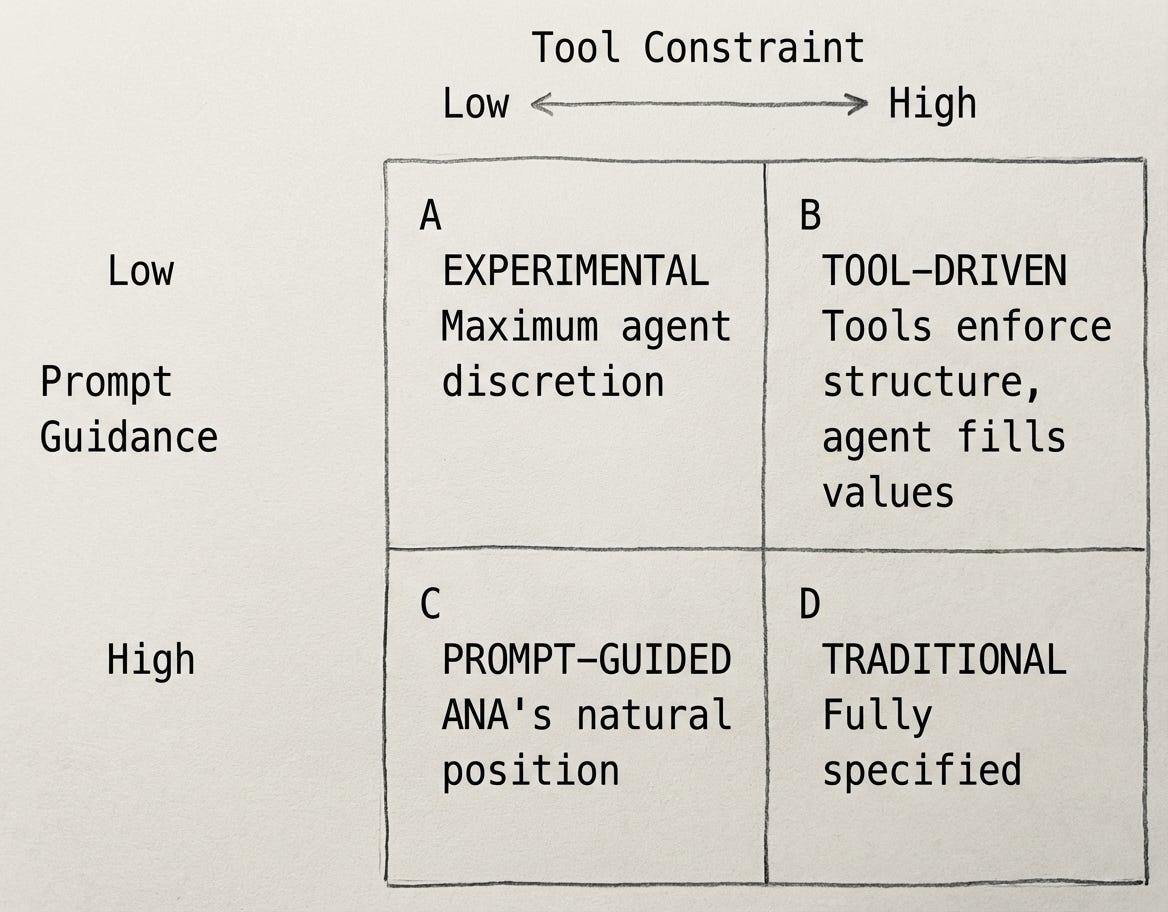
Experimental (A): Maximum emergence. The agent decides almost everything. High adaptability but unpredictable. Useful for research; risky for production.
Tool-Driven (B): Domain concepts encoded in tools. The agent translates natural language into predefined structures. Predictable but inflexible.
Prompt-Guided (C): Generic tools with detailed guidance. The agent has operational flexibility but follows conventions. This is a natural position for ANA implementations.
Traditional (D): Fully specified behavior. The agent has little discretion. At this point, you may not need an agent at all.
